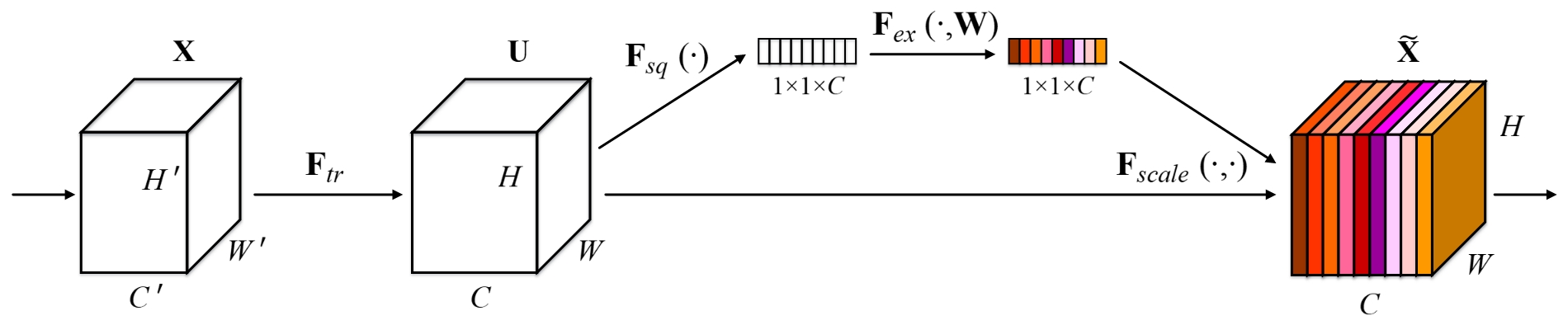
本篇主要记录一下2017年ILSVR竞赛的冠军-SENet,这是一种网络的block结构,可以有效的结合到InceptionNet,Resnet中。
本篇主要记录一下2017年ILSVR竞赛的冠军-SENet,这是一种网络的block结构,可以有效的结合到InceptionNet,Resnet中。
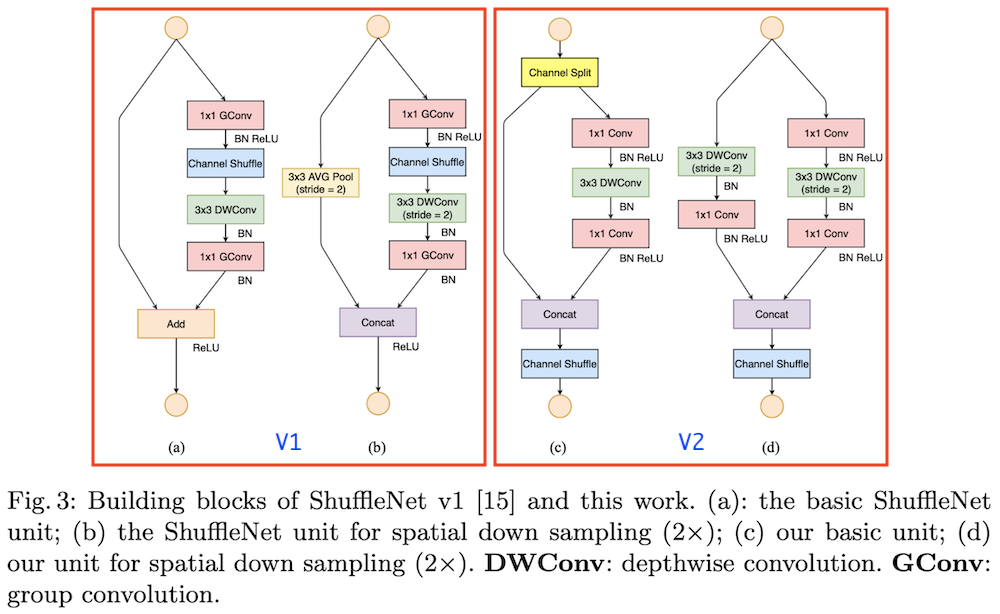
本篇主要分析轻量化Conv-ShuffleNet
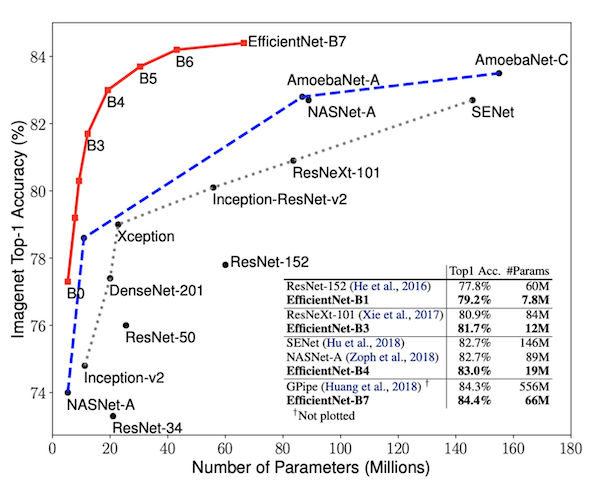
上图为不同模型的参数量和模型ACC曲线,可以看到和EfficientNet对比的网络包含ResNet,SENet,GPipe,Inception,NASNet,DenseNet等目前的主流网络,并且处于领先位置。

本篇主要总结一下卷积的不同的方式以特点,包括普通卷积,反卷积,空洞卷积,深度可分离卷积,可变形卷积等,如果有更新的方式出来了或者我看到了,继续更新在此。

本篇主要对目前流行的移动端轻量化网络MobileNet进行分析。
最近一段时间由于工作需要,想要将服务端的模型迁移到移动端,突然发现一个尴尬的现实,服务端的大模型在移动端是很难跑起来的。随着5G技术的到来,端上设备越来越强悍,将模型做到移动端是一个很显然的大趋势。目前的移动端模型 ( https://www.tensorflow.org/lite/models/ ),主要跑的是CV相关方面的识别,检测模型,姿态预估等相对简单的模型,并且目前的模型很多是基于MobileNet这一网络的,本篇就主要针对Mobilenet进行研究分析。
本篇涉及平时工作中使用的一些Python相关轮子,在此记录,不断补充更新……


BERT全名为(Bidirectional Encoder Representations from Transformers), 在NLP领域作为Word2vec的替代者,将NLP中的$11$项任务精度向前大大推进,作为一名算法工程师,非常有必要好好研究一下。
本篇主要记录在日常工作中遇到的TensorFlow的相关信息,包括如何处理报错信息,环境设置,训练测试,数据等等。
本篇详细说明了OCR的应用,技术实现,当前相关进展等,不定时补充更新。
本篇博客最初想写成一本掘金小册,可是掘金的那边看了我的提纲说太难了,应该没什么受众,额……,那我就自己写一下记录下来,不会太讲究斟词酌句了,希望见谅。
本篇博客算是一篇针对OCR相关学习或者初步接触者的引导和入门,讲的不深,实际上针对每个模块,比如CTPN,CTC,Attention,Densenet这些我都有专门写过博客来讲述过,感兴趣的可以翻翻我的博客文章。
更新记录:
2020.01.31: 自从19年4月份入职字节跳动之后一直忙于工作,很久没有更新个人博客了,今天看到各位的留言很是感动,为自己长久的拖延感到羞愧。由于武汉肺炎延迟开工,今天努力把以前写的提纲补充齐全,这一年来,相比于之前增加了更多的工业界算法思维,一个好的算法是在能够实现预定目的的同时,尽可能节省算力的,接下来也会把自己的一些感触和经验体现在博客里面。