本篇主要记录在日常工作中遇到的TensorFlow的相关信息,包括如何处理报错信息,环境设置,训练测试,数据等等。
如何安装
安装tensorflow或者ubunt时,优先使用清华镜像
地址:https://mirrors.tuna.tsinghua.edu.cn/help/tensorflow/
安装教程可以参考 https://www.tensorflow.org/install/source
在安装GPU版本的时候,要安装对应的cuda和cudnn文件,详细信息可以参考NVIDIA的官网,对于CUDA 和TensorFlow-GPU的版本对照,
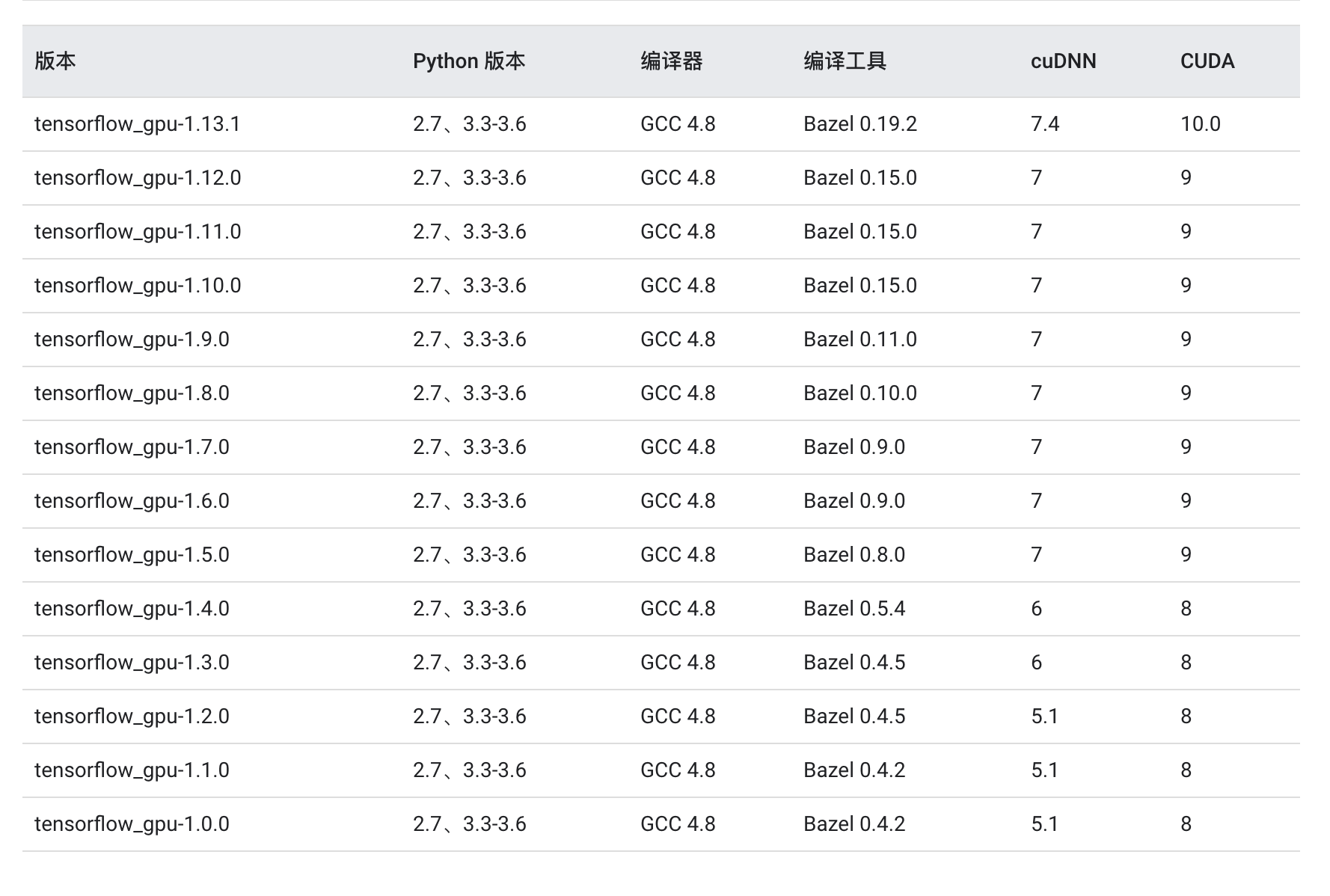
1. 安装pipeline
安装NVIDIA驱动
使用
nvidia-smi进行测试,如果没有该命令,需要安装,安装链接为https://www.nvidia.com/Download/index.aspx?lang=en-us ,如果已经安装,进入下一步安装cuda
首先要查询想要安装的TensorFlow版本与cuda版本的对应关系,可以在此处查询https://www.tensorflow.org/install/source,另外,补充TensorFlow1.14.0 对应cuda10.0
确认好版本之后在此处进行下载https://developer.nvidia.com/cuda-toolkit-archive 以cuda10+linux为例,当安装的是debain版本时,选择14.04的版本,因为cuda是向下兼容的,这样可以避免出错,
推荐下载runfile的方式,安装方式如下
1
2
3Installation Instructions:
Run `sudo sh cuda_10.0.130_410.48_linux.run`
Follow the command-line prompts按照提示一步步进行安装即可,最后在
.zshrc或者.bashrc中加入cuda的路径
安装cudnn
根据安装的cuda版本找到对应的cudnn版本,尽量选择runtime版本,下载完之后,进行安装
1
sudo dpkg -i xxx.deb
安装tensorflow
1
pip install tensorflow-gpu=1.14.0
API查询
https://www.tensorflow.org/overview?hl=zh_cn该网址保存着tensorflow的实例,操作手册和api查询
高质量仓库和博客
BLOG:
- 总览:https://www.tensorflow.org/overview
- 常用指令的用法:https://www.tensorflow.org/guide
- 常见模型:https://www.tensorflow.org/tutorials
GITHUB:
- 官方仓库:https://github.com/tensorflow/models/
- 高星仓库:https://github.com/aymericdamien/TensorFlow-Examples
报错信息及处理方案
CentOS安装TensorFlow:ImportError: /usr/lib64/libstdc++.so.6: version CXXABI_1.3.7’ not found
也有可能是这种信息,终端启动python,执行import tensorflow的操作出现的报错信息
1 | (tf) shixiaofeng@n8-035-087:~$ python |
遇到这种相关信息是因为动态库版本过低造成的。对于TensorFlow的model目前一般使用的是最低1.5版本,这就需要对TensorFlow进行编码的时候需要一定的动态库版本。
处理方式:
- 查看虚拟环境中的动态库版本,下面的代码是找到名称为tf的虚拟环境下的动态库版本
1
strings ~/anaconda2/envs/tf/lib/libstdc++.so.6 | grep 'CXXABI'
- 查看系统的动态库版本
1
2
3
4strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep 'CXXABI'
strings
或者
/usr/lib64/libstdc++.so.6 | grep 'CXXABI' - 如果发现系统的动态库版本较低并且就如报错信息所言,不存在需要的动态库版本,并且虚拟环境中的动态库版本较高,这个时候将虚拟环境下的动态库文件复制到系统环境下
1
2
3
4
5
6
7
8
9
10# cd到系统路径
cd /usr/lib/x86_64-linux-gnu
# 或者
cd /usr/lib64
# 查询libstd++版本文件
find . -name "libstdc++"
# 复制动态库文件到系统目录
sudo cp ~/anaconda2/envs/tf/lib/libstdc++.so.6.0.25 /usr/lib/x86_64-linux-gnu/
# /usr/lib/x86_64-linux-gnu/目录下在创建软连接
ln -snf ./libstdc++.so.6.0.25 ./libstdc++.so.6- 查看虚拟环境中的动态库版本,下面的代码是找到名称为tf的虚拟环境下的动态库版本
查看tf在cpu还是gpu
激活环境
1 | import numpy |
会得到运行信息
1 | 2019-04-03 16:20:34.035168: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA |
anaconda虚拟环境添加路径
如果是个人创建的环境,则目录为,针对的是anaconda2,当然要根据自己安装的anaconda版本确定路径。
1 | ~/anaconda2/envs/tf/lib/python2.7/site-packages |
如果是base环境
1 | ~/anaconda2/lib/python2.7/site-packages |
在目录下创建文件*.pth文件
1 | vim add_path.pth |
在文件下添加内容,如下针对的是对于目前本人使用的开发机
1 | /data00/home/xxx/repos/toutiao/lib/ |
如果想要cuda路径信息
1 | # 添加cuda8路径 |
也可以直接添加到~/.bashrc中
1 | export PATH=/usr/local/cuda-8.0/bin/:$PATH |
无法导入tensorflow
已经安装tensorflow,但是在import的时候会出现no module name tensorflow的错误信息
卸载tensorflow并重新安装
多GPU使用
Train
官方的参考链接
https://www.tensorflow.org/guide/using_gpu#using_multiple_gpus
https://www.tensorflow.org/alpha/guide/using_gpu?hl=zh_cn#using_multiple_gpus
官方代码,存在于tensorflow/model/
这个说的就是并行化,一般是模型并行化和数据并行化
- 模型并行化:不同的gpu保存的模型不同,输入的数据相同,共同训练,可以认为是一种bagging,一般Deeplearning用的不多
- 数据并行化:不同的gpu保存的模型是相同,输入的数据不同,共同训练,指定一个device来保存模型参数,分配给使用的gpu模型中,使用所有模型的平均梯度来进行参数更新,一般用的是这种方式。

使用Minist进行多GPU试验
1 | import tensorflow as tf |
Eval && Inference
在验证和测试的时候,每次输入的数据是单个数据,一般情况下无法进行拆分,因此,单gpu运算。如果增加服务器来处理大量的访问请求,要调用tensorflow serving,多个gpu不熟相同的graph,由tensorflow serving来控制请求的队列。
GPU选择
在运行tensorflow gpu时候,如果机器上存在多块显卡,并且没有在代码中进行多gpu设置,最好只用一块gpu,在运行程序的时候,可以使用如下命令
1 | CUDA_VISIBLE_DEVICES=0 python **.py |
如此,之后使用第一块gpu进行计算。
当然也有其他的设置方法,可以在程序中设置TensorFlow的device环境。
TensorRT
install
https://zhuanlan.zhihu.com/p/88318324
https://tbr8.org/how-to-install-tensorrt-on-centos/
TfRecord
TensorFlow推荐使用tfrecord的数据格式。
read
write
将tfrecord中的数据读出,只读取一个epoch, 也就是不进行重复读取,该代码不是为了进行模型训练,只是单纯的读取tfrecord中的数据并保存本地
1 |
|
Fintune
微调模型,一般指我们使用一些成型框架如VGG,GOOGLENET等,并在这个网络的基础上添加不同的网络训练层,以适应我们自己的任务。对于vgg等网络,一般是基于Imagenet预训练好的,因此我们没必要再重新从头训练,但是对于IMagenet是1000类,但是我们自己的任务很可能不是在这个数据集上进行的,为了快速训练模型,我们选用模型微调的方法。
加载一个预训练的模型,固定加载的这个模型的部分权重,只更新部分网络权重。
参考博客:https://blog.csdn.net/ying86615791/article/details/76215363
代码来源:tensorflow yolo3
1 | # 训练数据集 |
Export Graph
参考文章:
https://blog.csdn.net/guyuealian/article/details/82218092
当训练好模型之后,默认会得到一些训练的权重文件

- checkpoint文件保存着模型文件的路径

- model.ckpt.meta保存了TensorFlow计算图的结构信息
- model.ckpt保存每个变量的取值,此处文件名的写入方式会因不同参数的设置而不同,加载restore时的文件路径名是以checkpoint文件中的“model_checkpoint_path”值决定的
在ckpt文件夹下面,存储着的信息包含着整个模型的全部信息,这些信息很显然是可以进行模型的重新加载的,但是有一些信息是没必要的,尤其是在进行测试阶段的时候,在inference的时候,只需要加载已经训练好的权重参数即可,该阶段只有正向传播,没有反向传播过程,只需要告诉模型如何输入如何输出即可,不再需要想训练阶段那样要进行模型初始化,模型保存,优化参数等设置。在tensorflow中推荐将模型进行固化的方式,只保留模型的参数。
具体实现代码为
1 | import os, argparse |
上述代码可以完成将ckpt中文件的固化,并输出frozen_model.pb文件,该文件中保存着模型的参数。
那么如何加载已经固化的文件呢?代码如下
1 | import tensorflow as tf |
加载*.pb文件并返回模型的graph
下载数据集COCO&VOC
VOC数据集地址
1
2
3wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tarCOCO数据集
1
2
3
4wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip代码实现
Reference from tensorflow model
1 | #! /usr/bin/env python |
Use the wget
1 | #! /usr/bin/env python |
直接执行
1 | python xxx.py --dataset coco |
可以直接下载coco数据集到设置的位置,并将数据集解压缩
OpenImage 下载
由于OpenImage文件较多,单次下载非常慢,特此保存一个下载脚本,输入想要的模型名称,下载openimage中对应的数据图片和标注信息
1 | import time |
可以使用如下方法进行下载
1 | python open_images_downloader.py --root ~/datas/openimage --class_names_file dataset/awesome_open.names --num_workers 500 |

