最近和同学@liguoqing.sant有聊到图像检索相关方面的工作,主要是这么一篇论文 Learning Non-Metric Visual Similarity for Image Retrieval,本篇文章主要结合个人理解来记录一下这篇论文。
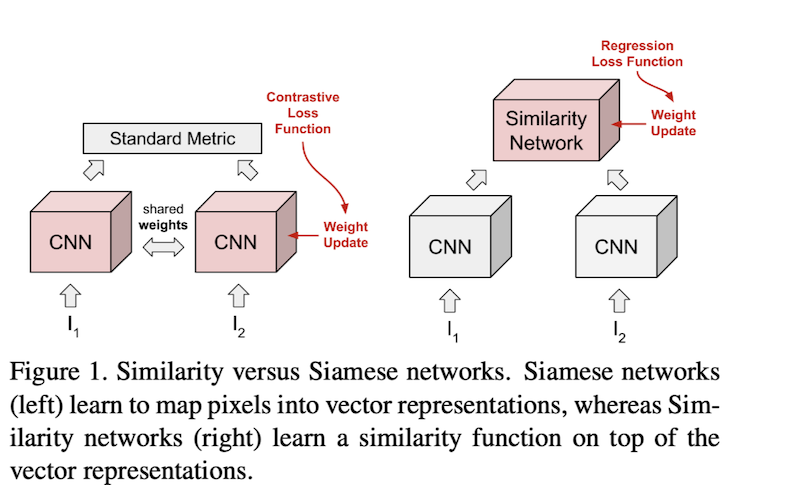
如图,左侧是我们常用的度量学习方法,右侧是本论文提出来的使用一个similarity-network来代替常用的线性度量方程。
在进行图像检索的时候,一般是通过query图像和doc图像之间的相似度来进行检索。这里的样本之间相似度的度量方式可以认为是一种metric,一般使用余弦距离,或者欧式距离来表示相似度,这种计算样本之间相似度的方法是线性的。
在说Non-Metric之前,先说一下什么是metric-learning。
Metric learning
关于度量学习,在知乎或者csdn上面都有不少的资料机器学习: Metric Learning (度量学习),Deep Metric Learning,简单来说度量学习就是学习一个度量相似度的函数,最终的目标是相似的目标离得近,不相似的离得远。就像开篇那副图左侧那样,通过cnn抽取图像特征,使用cosine或者euclidean的方式计算样本对的相似度。
基于pair/triplet方式的triplet-loss,center-loss或者contrast-loss以及基于softmax的arceface-loss, circle-loss等都是在metric learning的基础上设计的loss,优化的目标更多的是特征提取网络。
Non Metric
这里的这个论文是一种非线性的Non-Metric的方法来计算样本之间的相似度。
看完论文之后,这篇论文的的设计思路比较有意思,使用一个similarity-network来代替cos_distance或者euclidean_metric的方式来计算输入样本对之间的相似度,这个similarit-network的参数是可学习的。之所以这么设计是因为在计算样本对相似度的时候,我们从人的角度出发,一般情况下对样本对的相似度的要求是
- 非负性,d(a,b)>=0
- 等价性,d(a,b)=0 等价于 a=b
- 交换性,d(a,b)=d(b,a)
- 三角不等性,d(a,b)<=d(a,c)+d(b,c)
我们平时使用的相似度度量方式,不论是cosine还是euclidean的方式,都或多或少的不满足上面的四个要求。这也是这一篇文章的设计原因,既然现在的相似度度量方法和我们认为的相似度不太一致,那直接搞一个网络来计算两个样本的相似度岂不美哉,还省了很多的推导和公式设计。
本篇中所说的similarity-network就是一个输出维度为1的全连接网络,并且这里使用的除了最后一层,其余层全部使用的relu激活函数,之所以使用relu,一个是为了使得特征稀疏,一定程度提升模型的鲁棒性,另一个感觉是基于上面非负性要求的设计。
训练方法
训练的过程如下
预训练的CNN网络提取图片特征,这一部分权重固定
将一个pair的feature进行拼接,拼接的维度是[Batch,dimx2]
两层全连接层,中间的激活函数是Relu,最终输出维度为1
Loss设计
$$
\begin{aligned}
\mathcal{L}\left(I_{i}, I_{j}\right)=| s_{i, j}-\ell_{i, j}\left(\operatorname{sim}\left(x_{i}, x_{j}\right)+\Delta\right) \
-\left(1-\ell_{i, j}\right)\left(\operatorname{sim}\left(x_{i}, x_{j}\right)-\Delta\right)
\end{aligned}
$$
其中
$$
\ell_{i, j}=\left{\begin{array}{ll}1 & \text { if } I_{i} \text { and } I_{j} \text { are similar } \ 0 & \text { otherwise }\end{array}\right.$
$$- Label: 根据CNN特征和标注数据来确定label
- 如果标注当前pair相似,那么在cos(emb1,emb2)的基础上加上margin,让相似的相似度更高
- 如果标注当前pair不相似,那么在cos(emb1,emb2)的基础上减去margin,让不相似的相似度更低
- 使用FC输出的logits来回归label,使用MSE损失
- Label: 根据CNN特征和标注数据来确定label
网络设计的很简单,解决的任务也很简单,就是用这个similarity-network代替cosine/euclidean的方式,来计算样本之间的相似度,用这个相似度来进行图像检索。
思考
看这篇文章的时候,刚开始没太明白,以为这是一种可以替代triplet-loss或者pair_loss的的新的训练网络的方法,看到后面明白本论文解决的是特征之间度量的问题。
###解决什么问题?
在平常进行图像检索或者reid领域,实际上很重要的一点是设计更高效的loss来训练特征提取网路,如果这个网络训练好了,一般直接使用cosine的方式或者归一化向量內积的方式来表征不同样本之间的相似度。这篇文章解决的就是CNN网络训练好了之后的事情。
论文实验对比公平吗?
先说结论,个人感觉论文中的结果对比是不公平的。
这篇文章给出了一个很有意思的结论,当similarity-network训练的数据比较好的时候,对比cosine优势明显,当训练数据不太好的时候,那么cosine是更好的选择。
consine可以看成是一个线性变换,就是一个简单的公式,而这个网络使用的使用了两个特征拼接经过FC再回归计算loss的方式,个人感觉这种对比方式是不公平的。
- consine的方式在测试的时候是不需要训练的,而similarity-network需要训练,不管在什么数据集上,在训练集训练,在测试集测试,这个时候similarity-network是见过类似的数据的,这样直接对比consine是不公平的,应该使用同样的方式,给cosine的也引入两个fc层,并且在同样的数据进行训练,只不过换成直接优化cosine的方式,个人感觉这样才相对公平。
- Loss设计的时候使用的cosine和margin,对比的目标是cosine,这个天然就是不合理的。
总结
- 在工业界similarity-network的设计思路可以相对更快速适配新的检索特征。
- 在学术界这有可能被当成一篇灌水文章。
- 模型设计很简单,参数很少,没有可以学习到的trick。
- 探讨了不同fc的隐藏层节点数得到的结果,直白讲,节点越多结果越好,参数量越大,这个要取一个trade-off。
审稿人@liguoqing.sant

