本篇主要分析轻量化Conv-ShuffleNet
ShuffleNetV1

ShuffleNet是$2017$年由Facebook提出的,它的主要竞争对手是Google提出的MobilenetV1,上图作者在论文中与MobileNetV1在ImageNet的的对比。
Overview
ShuffleNet网络主要是针对的Xception和ResNet,由于$1 \times 1$卷积部分的计算开销在小型网络中不够理想的问题。受depthwise卷积的启发,每个通道都与一个卷积核进行计算,那么在$1 \times 1$这部分卷积中,一个很自然的方法就是,对当前的featuremap的通道进行分组计算,但是如果直接分组的话,就造成了不同特征的隔离,不同的组之间的特征无法交互,这样做显然会造成数据特征的丢失,效果不好。ShuffleNet就是针对这个问题提出的解决方案,对featuremap的通道进行分组进行group convolution,然后每组输出的featuremap进行重排channel shuffle,这样不同组的的信息由此得到交换,并没有完全隔离,能在较小计算量的情况下保持较好的精度。
不同featuremap分组方式对比

图$a$,是将featuremap的通道进行分组,显然这样会造成特征之间的隔离,输出只有一部分输入决定;图b/c在第一步卷积后对分组的通道进行重排,这样下层的输入就会接收到上层所有channel的数据,效果相比图$a$更好。
在图c中可以看到,channelshuffle层,在进行group convolution之后,对得到的通道进行shuffle,这里的shuffle不是随机的,而是均匀的打乱。在程序上的实现方法很简单:假设将输入层分成g组,每组的数量为n,那么总的通道数为$g \times n$,将通道拆成两个维度$(g,n)$,然后将这两个维度进行转置$(n,g)$,最后reshape成一个维度,这样得到的维度就是均匀shuffle之后的channel了,也就是图c中的channel shuffle的样子。
代码实现如下
1 | class ShuffleBlock(nn.Module): |
网络结构
在ShuffleNet中,也是和ResNet等模型相似,使用的是Block,结构如下所示。

图$a$是ResNet中的Block结构,图$b$是ShuffleNet中使用的Block,先经过$1 \times 1$通道分组卷积,然后通道重排,在$3 \times 3$空间上的depthwise convolution,然后再经过一个$1 \times 1$的通道分组卷积,图$c$是要进行降维时候的结构$stride=2$,旁边的shortcut也变为$stride=2$的平均池化。
可以看到shufflenet中的blcok是从残差网络的block中改造得到的。在resnet中block模块的设计是:$1 \times 1$的卷积–>$3\times 3$的深度卷积,并且在这一步数据通道减少,可以理解成一个bottleneck–>$1 \times 1$卷积,最后是一个短路连接,将输入直接加到输出上。
1 | 1x1 Conv --> 3x3 DWConv--> 1x1 Conv --------> |
在shufflenet中对resnet的block进行了改进设计,将$1 \times 1$的普通卷积换成了组卷积,并且在后面加入了channel shuffle操作。
1 | 1x1 Group convolution --> channel shuffle --> 3x3 DWConv--> 1x1 Group convolution --------> |
ShuffleNet的block设计代码如下所示
1 | class Bottleneck(nn.Module): |
下图是shufflenet的模型结构示意图

开始是普通的$3 \times 3$的卷积,和maxpool层,然后是3个stage,每个stage都是重复堆叠shufflenet中的block结构,在每个stage中,第一个基本单元采用的是$stride=2$,这样特征图width和height各降低一半,而通道数增加1倍。后面的基本单元都是$stride=1$,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这里和resnet中的残差单元设计是一致的。
总结
实际上就像开头说的那样,shufflenet的设计的竞标对象是mobilenetv1,在论文中也可以看到作者的实验中对比对象是MobileNetV1。
可以看出来,shufflenet在计算复杂度和模型准确率上都是由于mobilenet的。
ShuffleNetV2

在ShuffleNet中,作者使用FLOPS来作为模型效率的一个评价指标,但是在在ShuffleNetV2的论文中作者指出这个指标是间接的,因为一个模型实际的运行时间除了要把计算操作算进去之外,还有例如内存读写,GPU并行性,文件IO等也应该考虑进去。最直接的方案还应该回归到最原始的策略,即直接在同一个硬件上观察每个模型的运行时间。如上图所示,在整个模型的计算周期中,Conv耗时仅占$50 %$左右,如果我们能优化另外$50 %$,我们就能够在不损失计算量的前提下进一步提高模型的效率。
在ShuffleNetV2中作者从内存访问代价(Memory Access Cost,MAC)和GPU并行性的方向分析了网络应该怎么设计才能进一步减少运行时间,提高模型的效率。
高效模型的设计原则
相同输入输出情况下MAC最小
对于一个featuremap,假设尺寸为$h \times w \times c_{1}$,经过卷积之后输出的featuremap为$h \times w \times c_{2}$,那么卷积操作需要的算力FLOPs为$B=hwc_{1}c_{2}$,在计算过程中占用的内存,输入featuremap为$hwc_{1}$,输出featuremap为$hwc_{2}$,卷积核为$c_{1}c_{2}$,也就是$MAC=hw(c_{1}+c_{2})+c_{1}c_{2}$
有如下的推导公式
$$
\begin{aligned}
M A C&=h w\left(c_{1}+c_{2}\right)+c_{1} c_{2}\
&=\sqrt{\left(h w\left(c_{1}+c_{2}\right)\right)^{2}}+\frac{B}{h w}\
&=\sqrt{(h w)^{2} \cdot\left(c_{1}+c_{2}\right)^{2}}+\frac{B}{h w}\
&\geq \sqrt{(h w)^{2} \cdot 4 c_{1} c_{2}}+\frac{B}{h w}\
&=s \sqrt{h w \cdot\left(h w c_{1} c_{2}\right)}+\frac{B}{h w}\
&=2 \sqrt{h w B}+\frac{B}{h w}
\end{aligned}
$$
当满足$c_{1}=c_{2}$的时候,上式可以取到等号,也就是说,当所需算力确定的前提下,$c_{1}=c_{2}$时所需的MAC最小,此时的模型效率最高。
MAC与group convolution的分组数量成正比
在group convolution中,FLOPs为$B = hwc_{1}c_{2}/g$,对应的MAC计算公式为
$$
\begin{aligned}
M A C &=h w\left(c_{1}+c_{2}\right)+\frac{c_{1}}{g} \frac{c_{2}}{g} g \
&=h w\left(c_{1}+c_{2}\right)+\frac{c_{1} c_{2}}{g} \
&=B g\left(\frac{1}{c_{1}}+\frac{1}{c_{2}}\right)+\frac{B}{h w}
\end{aligned}
$$
也就是在使用group convolution的时候,group的分组数量不要太大。
模型的分支会降低网络并行能力
在比较典型的模型结构中,InceptionNet和NasNet是分支比较多的,在论文里,作者对比了几种不同的网络结构,通过控制卷积的通道数来使5组对照试验的FLOPs相同,通过实验我们发现它们按效率从高到低排列依次是$a>b>d>c>e$

可以明显的看到,模型的效率和模型的分支数量是成反比的。
ElementWise操作是很昂贵的
所谓的ElementWise是指在模型网络中的激活函数,bias_add等操作,这些操作在计算FLOPs时被忽略掉了,但是根据上面论文中作者提供的shufflenetv1和mobilebnetv2的计算时间分布饼图,可以知道ElementWise实际上所占的比例一点都不小。
总结
既然有了上面四个设计准则,那么要想设计更高效的网络就有了入手点
- 使用输入通道和输出通道相同的卷积操作
- 谨慎使用分组卷积
- 减少网络分支数
- 减少
ElementWise操作
在shufflenetv1中设计的block中有两个分组卷积层存在,并且每个分组卷积层group数量一般为3,这显然就不满足第二个准则了,回顾MobileNetV2的结构借鉴了resnet的设计,包含深度可分离卷积,扩展层和映射层以及大量的Relu6操作,显然不太符合条件3,4。
网络结构
上面说了一大堆,主要是作者在阐述shufflenetv2的设计思路,那么网络结构到底啥样子
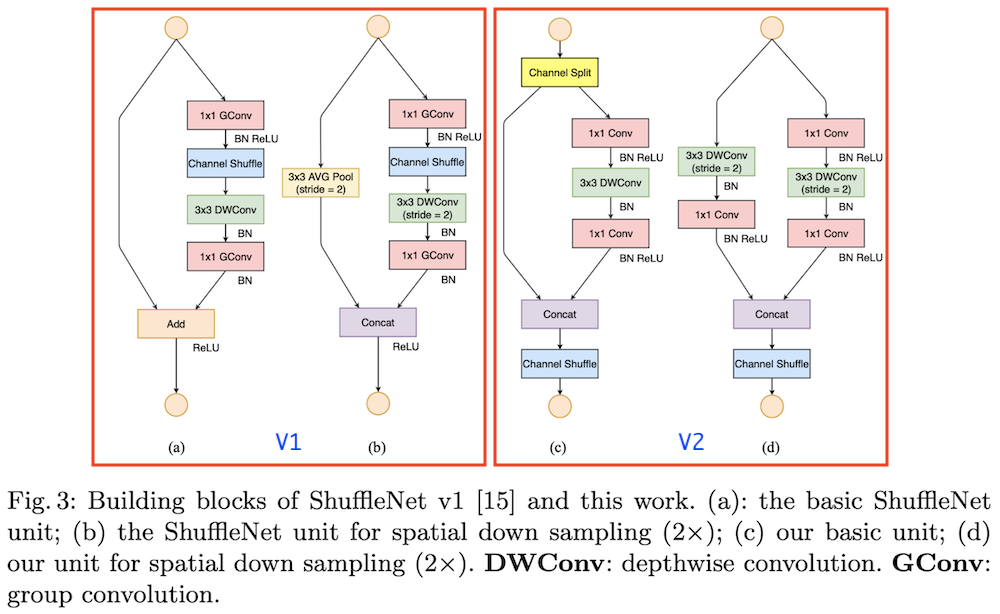
左边两个是第一节中所说的V1的结构,右边是需要重点说的V2的结构。
对比发现
- $c$中加入了通道分割操作(channel split),具体的操作方法是:将c个输入的feature分成$c-c^{1}$和$c^{1}$两组,并且一般情况下$c^{1}=\frac{c}{2}$,这样是为了满足设计准则的第三点,尽量控制模型的分支数量
- 进行通道分割之后左侧的分支直接映射,右侧是一个输入通道数和输出通道数相等的深度可分离卷积,这样是为了满足条件1
- 右侧的分支中只使用了$1\times1$卷积,并没有使用V1的分组卷积,这样是为了满足条件2
- 在最后合并的时候都是使用的concat操作,并没有使用Add,是为了满足条件4
- 在堆叠
ShuffleNetv2的时候,concat,channel-split和channel-shuffle合并成1个element-wise操作,也是为了满足条件4。
图$d$是降采样操作,不进行channel-split操作,每个分支直接copy一份输入,每个分支进行stride=2的下采样,最后concat在一起,这样featuremap减半,但是通道数量加倍。
其他的地方就和V1模型相似了,通过多个block堆叠,组成ShuffleNetV2模型,模型结构如下

V2相比V1多了一个conv5层,除了这个外就没什么不一样的了。

