
本篇主要对目前流行的移动端轻量化网络MobileNet进行分析。
最近一段时间由于工作需要,想要将服务端的模型迁移到移动端,突然发现一个尴尬的现实,服务端的大模型在移动端是很难跑起来的。随着5G技术的到来,端上设备越来越强悍,将模型做到移动端是一个很显然的大趋势。目前的移动端模型 ( https://www.tensorflow.org/lite/models/ ),主要跑的是CV相关方面的识别,检测模型,姿态预估等相对简单的模型,并且目前的模型很多是基于MobileNet这一网络的,本篇就主要针对Mobilenet进行研究分析。
MobileNetV1
同样是针对移动端进行优化,使用mobilenet替代常规的卷积方式,由于Mobilenet的深度可分离卷积结构设计,目前,在工业界Mobilenet是移动端部署使用最广泛的,到2019年已经公布了MobilenetV3版本,该网络被广泛用于移动端的图像识别,检测等任务。
论文链接🔥 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
设计思路
在进行小型高效的神经网络时,一般两种思路:
压缩模型
获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,例如上面的
squeezenet。直接训练小模型
例如
Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet使用一个bottleneck用于构建小型网络。
深度可分离卷积
Mobilenet主要注重于优化延迟的同时考虑小型的模型,从深度可分离卷积的角度构建模型。
mobilenet基于深度可分离卷积,将标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution),通过此举大幅度降低参数量和计算量
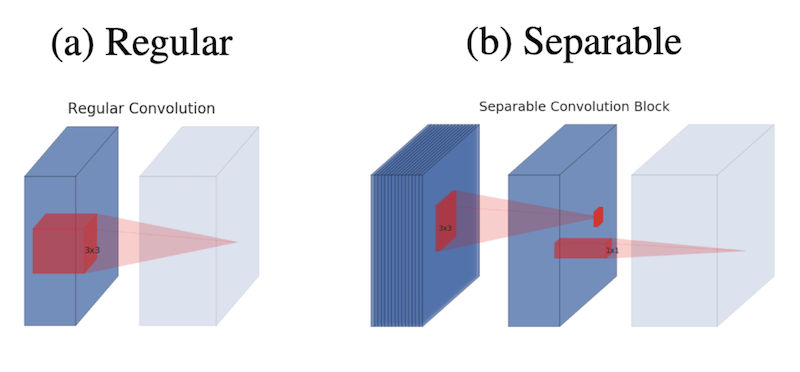
图中的浅色代表的是下一个block的开始,并且注意方块代表的是特征图,而红色映射才是卷积或者ReLU操作。$a$表示的是普通卷积方式,$b$表示的就是在MobileNet中广泛使用的深度可分离卷积(Depthwise Separable Convolution),先进行Depthwise再进行Pointwise
普通卷积计算
假设输入的
featuremap为$12 \times 12 \times 4$,卷积为conv_3-2,则对应的计算量为$12\times12\times2\times(3\times3\times4)=10368$,参数量为(卷积核带来的参数) $3\times3\times4\times2=72$,如下图所示
image comes from https://blog.csdn.net/huachao1001/article/details/79171447
深度可分离卷积
在
Mobilenet中将卷积操作进行了分解,分解为深度卷积和逐点卷积
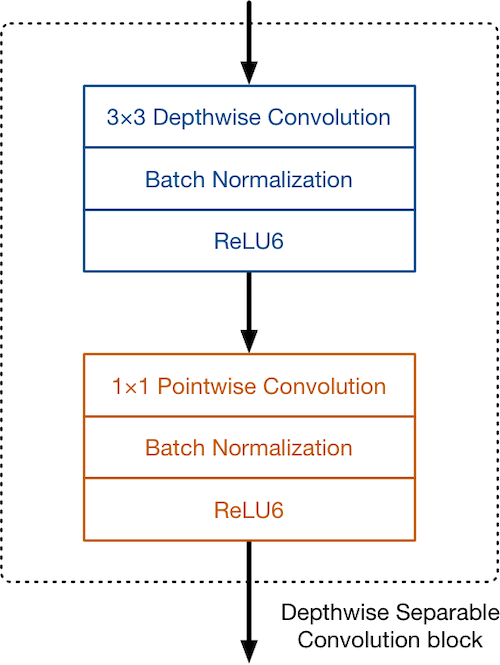
深度卷积DepthwiseConvolution与传统的卷积方式不同
对于传统的卷积,卷积核在输入特征图的所有通道上共享参数,输出的通道数由卷积核的数量决定
深度卷积对输入的特征图的每个通道上使用不同的卷积核,一个卷积核对应一个输入通道
所以可以说DepthwiseConvolution是depth级别的操作。
对于这一步的深度卷积有一篇回答特别棒 https://stackoverflow.com/questions/45369920/tensorflow-what-exactly-does-depthwise-convolution-do
为防止链接挂掉,引用代码如下
1 | import tensorflow as tf |
PointwiseConvolution其实就是普通的卷积,只不过采用1x1的卷积核。假设输入为M*N*C,原来的卷积为conv3-k,对应着k个3x3的卷积核,输出为M*N*k,现在将其进行改变成两步进行
- 第一步:depthwise conv—输入为
M*N*C,卷积为conv3-1,输出为M*N*C - 第二步:pointwise conv —输入为
M*N*C,卷积为conv1-k,输出为M*N*k
最终输出的feature map尺寸相同,但是会很大程度减少参数量。
使用和普通卷积同样的参数进行演示,如下所示,输入的feature map的尺寸为$12 \times 12 \times 4$
第一步
DepthwiseConv—卷积为conv3-1,计算量:$12 \times 12 \times 1\times 3 \times 3 \times 4 = 5184$
参数量:$1\times 3 \times 3 \times 4=36$
对$4$个通道每个通道都与一个$3\times3$的卷积核计算
输出的特征图大小为$12\times12\times4$
第二步
PointwiseConv-卷积为conv1-2,输入的尺寸为$12 \times 12 \times 4$- 计算量:$12 \times 12 \times 2 \times (1 \times 1 \times 4)=1152$
- 参数量: $2 \times (1 \times 1 \times 4)= 8$
- 输出特征图大小为$12 \times 12 \times 2$

比较普通卷积计算方式和mobilenet的计算方式,可以看到参数量由$72$较少到了$44$;计算量由$10368$减少到了$6336$。
深度可分离卷积可以看做是InceptionNet中的结构的极致设计,详细分析在这里👉👉👉
网络参数
对Mobilenet的网络参数如下图所示

除了在最后的全连接层没有使用非线性激活函数,其他层均使用BN+Relu6策略。
MobileNetV2
论文链接🔥 MobileNetV2: Inverted Residuals and Linear Bottlenecks
参考链接
V2相比于V1版本的升级
针对MobileNet进行升级,开发了V2版本,在V1版本中核心点是深度可分离卷积,在MobileNetV2中仍然采用的是深度可分离卷积,不同的是在此基础上又引入了残差结构以及bottleneck瓶颈层,MobileNetV2的可以看成一系列Bottleneck residual block的结构的堆叠,如下所示

不同的点这里说明一下:
自上而下对MobileNetV2中使用的Block进行分析
ExpansionLayer扩展层,这一部分使用的是$1 \times 1$ 的卷积,作用是为了扩充输入当前Block的特征图的通道数量,因此,扩展层始终具有比输入通道更多的输出通道。通道数量的扩展量由扩展因子决定。这是一个超参数。默认扩展因子为6,也就是扩展通道数$6$倍。
DepthwiseLayer
这里的深度卷积与
MobileNetV1中是相同的,不变换通道的数量,这里主要是为了参数量。ProjectionLayer
投影层。在这一层可以理解成pointwise,使用的是和
MobileNetV1中相同的$1 \times 1$卷积,这里区别于MobileNetV1的地方:- 在MobileNetV1中,pointwise的输出通道数量保持不变或者加倍
- 在MobileNetV2中,输出通道数量减少
这也是为什么在
MobileNetV2中这一层被称作投影层。在这一层,通道数量减少,可以理解成创建了一个高纬度到低纬度的映射。
每个Block的输出都是将输出的维度进行从高纬度到低纬度的变换,这也是每个block叫做bottleneck residual block的原因
下图为MobileNetV2中Bottleneck residual block示意图。

假设输入的通道数为24,经过expansion层之后,扩展$6$倍,变成$144$层,经过depthwise层,通道层数不变,经过projection层,通道数变为$24$,使用ResNet相同的方式连接Block的输入和输出,也就是进出模块的的特征图是低纬度的,在Block内部则是高纬度的,这就是MobileNetV2中广泛使用的结构。
在每个Bllock中,每个层都是BN+Relu6,除了最后一步的ProjectionLayer,在ProjectionLayer中没有使用激活函数,由于这一层的作用是进行从高通道数向低通道数的映射,使用非线性激活会使得有效信息丢失,在这里模型中使用的直接就是线性映射,没有使用激活函数。
整个MobileNetV2使用了$17$个Block结构进行串联叠加(第1个Block稍有不同,它使用具有32个通道的常规$3 \times 3$卷积代替扩展层中的$1 \times 1$卷积),最后就是标准的卷积核全局池化和分类层(这个是为适配图片识别任务,将MobileNetV2当做其他任务的基础网络的时候,这一部分不需要。)
V2升级的动机
在V1中,模型设计的出发点是减少卷积的参数量并且减少计算量,即便使用更多的层数也没关系,因此在V1中引入了深度可分离卷积,事实证明这个方法是可行的,在V2中,相比与V1的变化主要在借鉴ResNet的残差连接和Block中的ExpansionLayer和ProjectionLayer。
分析MobileNetV2的结构可以看到,在整个模型中各个Block之间数据的通道数都是很小的

由于ProjectionLayer的存在,使得相邻Block之间传递的数据维度很小,这很大程度减少了模型的计算量。但是只使用低纬度的数据特征,无法有效的提高模型的准确性,这个问题由ExpansionLayer来解决,该层的设计使得在每个Block中扩大输入当前特征图通道的数量,并且由于残差模块的存在,该层能够显著的提高模型的表达能力。
一个很有意思的解释:ProjectionLayer可以理解成为了减少计算量对数据进行的压缩,ExpansionLayer可以理解成为为了更好的表达特征图,对压缩过的数据进行解压缩,流经Depthwise的数据可以看做是真实的数据维度。
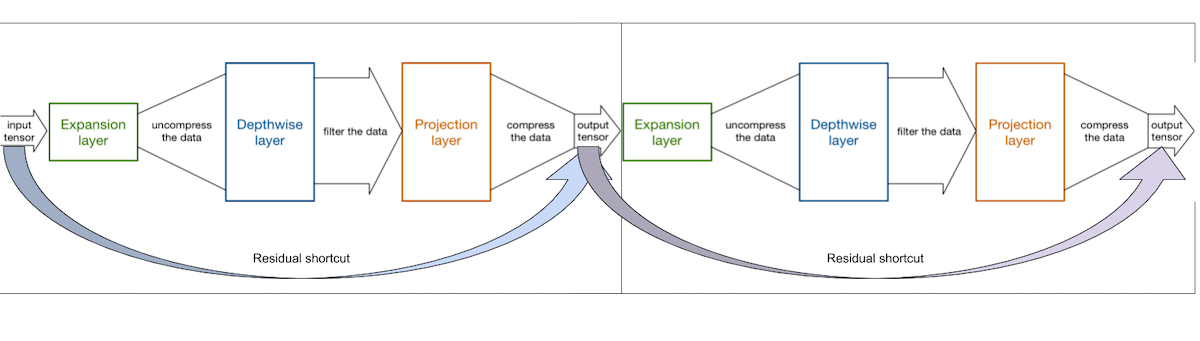
从图中可以看出,在每个Blcok模块中首尾链接,内部对数据解压缩(expansion),进行depthwise卷积操作,然后对数据进行压缩(projection),传递到下一个block中。
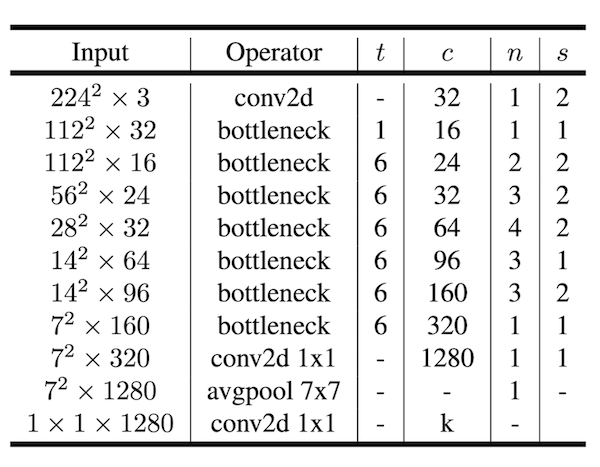
如上所示便是MobileNetV2的模型结构,t表示的是expansion层的扩展系数,c是输出的通道数,n表示当前block重复了几次,s表示步长
总结
先上图,这是MobileNetV2和其他移动端模型的对比。
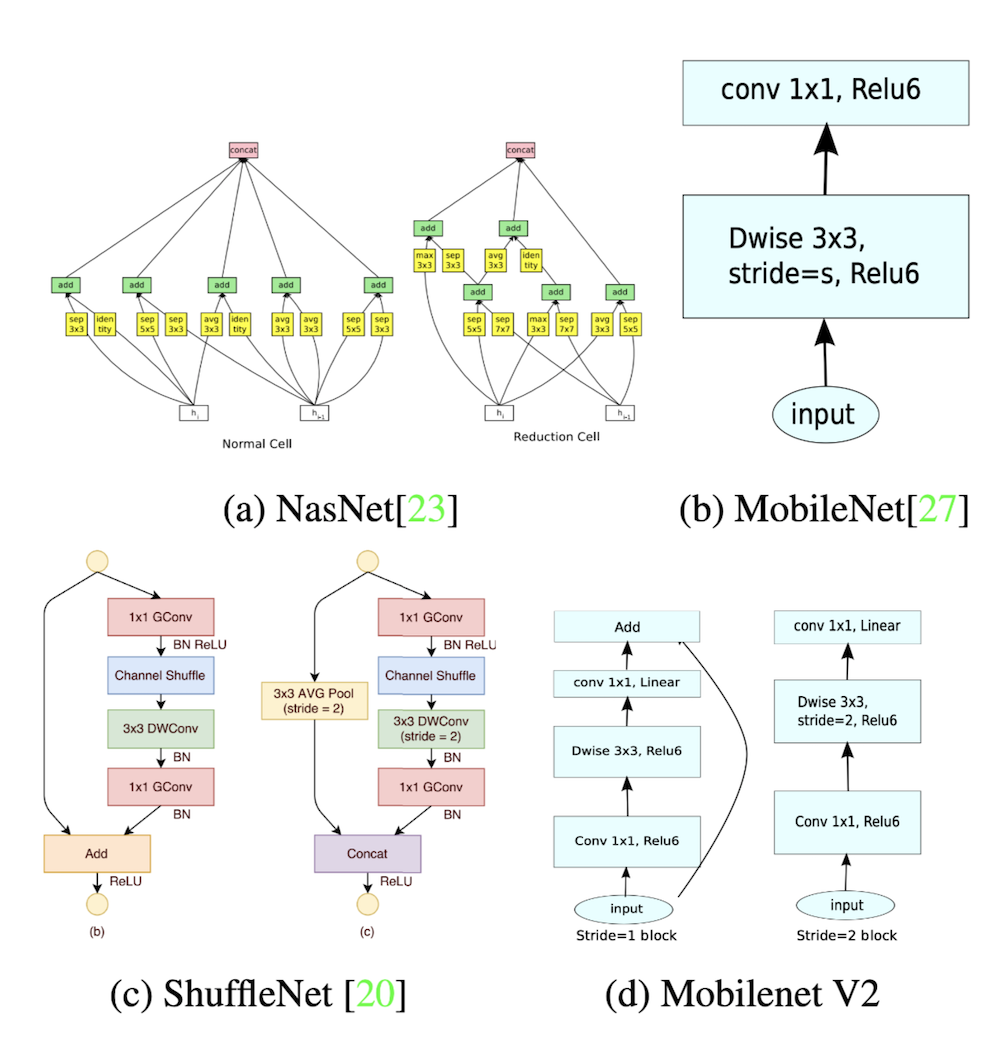
MobileNetV2是在V1的基础上升级而来,当然它的竞品是其他的轻量卷积模型shufflenet,nasnet这些。
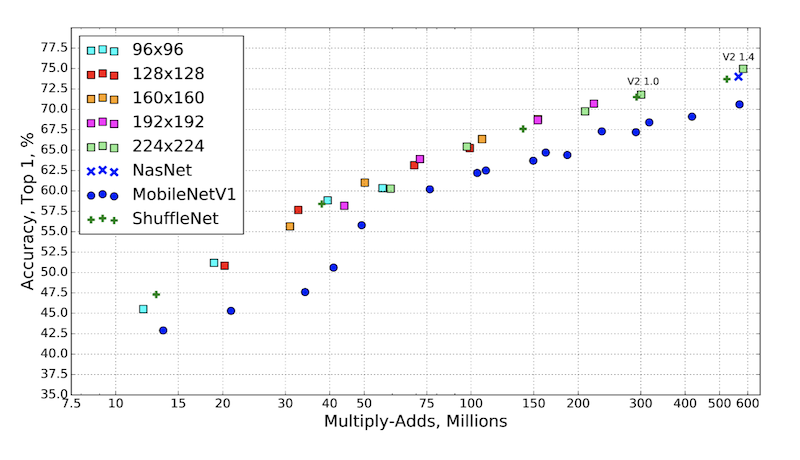
在对比指标中可以看出来,MobileNetV2相比于几个网络时更有优势的。

