本篇主要记录一下2017年ILSVR竞赛的冠军-SENet,这是一种网络的block结构,可以有效的结合到InceptionNet,Resnet中。
Block结构
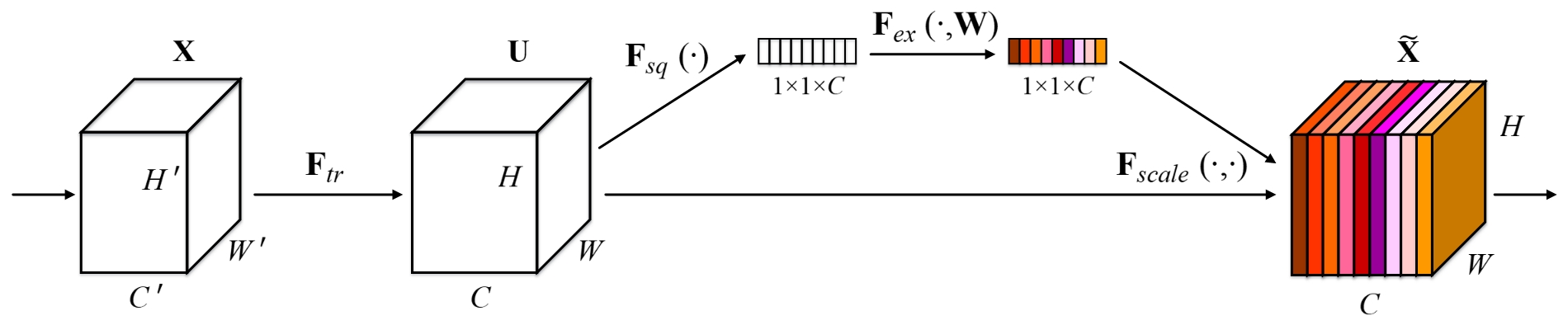
网络结构如上图所示,图中参数解释:
- $F_{tr}$–标准卷积操作
- $F_{sq}(.)$–sequeeze操作,这一步进对输入的特征图进行GlobalPooling,特征图由$H \times W \times C$变为$1 \times 1\times C$
- $F_{ex}(.)$–excitation操作,这一步包含两个fc全连接操作
- 第一步FC-压缩维度数量,维度数由$C$变为$C/r$,Relu激活层
- 第二步FC-扩展维度数量,维度数由$C/r$变为$C$,Sigmoid激活层
- $F_{scale}(.)$–类似通道注意力,将得到的C维度的值作为权重乘到输入的特征图的维度上。
参数和结构是如何确定的
扩展层压缩比
在论文中,作者认为压缩比为16可以取得模型的精度和运算复杂度之间的平衡,并且作者在论文中提出,由于模型的不同层在整个模型中的作用不一样,因此,在整个模型中使用同一个固定的压缩比不是一个最好的办法,可以设置不同的压缩比以适应不同的基础网络,我们在日常使用的过程中可以先使用16,之后在模型优化的时候再通过更改压缩比来进行对比试验。
压缩层
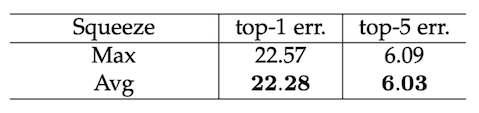
在sequeeze层中,对比研究了GlobalMaxPooling和GlobalAvgPooling,从指标身上看GlobalAvgPooling表现会更好一些,但是Maxpooling的计算更加简单,因此在模型中使用的是Maxpooling,这一步也是可以在个人实践的时候进行优化的。
扩展层计算方法
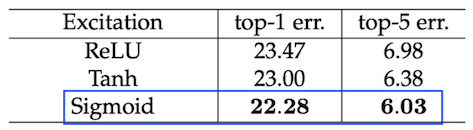
这里主要是讨论选择什么样的激活函数,众所周知常用的激活层是Relu,Sigmoid,Tanh。可以看到Tanh相比Sigmoid表现差一点,并且使用了Relu的Se-Resnet50已经低于了Resnet50的基线表现。这一步使用什么样的激活函数是很重要的,不是想当然的认为这一步要得到0~1之间的数,所以要使用Sigmoid激活函数,任何一个网络模型的设计都是要有依据的。
Block结构设计
为什么选择开篇图中那种Block的设计方式,论文中,作者研究了不同的网络结构设计如下

具体的表现为
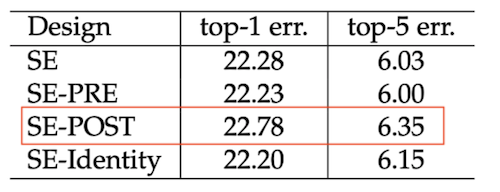
可以看出来,SE-POST表现相比是最差的。如果SE单元在分支聚合之前应用,则SE单元所产生的性能改进对其梭子的位置比较鲁棒的,表现差别不大。
正常情况下,每个SE块都放置在残差单元的结构外部。 论文中作者还构造了一种设计变体,将SE块移动到剩余单元内,将其直接放置在3×3卷积层之后,虽然论文中作者没给出是哪种block,但是个人感觉应该是瓶颈残差模块。
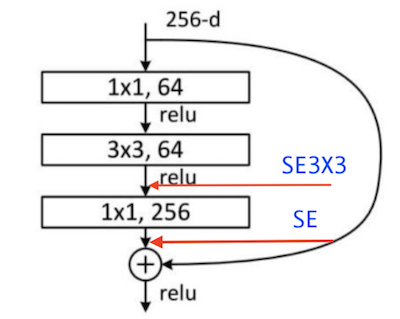
由于3×3卷积层具有较少的通道,因此相应的SE块引入的参数数量会想要减少。从下面的图标可以看出来,SE3x3与标准的SE相比,在减少10%左右参数量的情况下,并没有明显降低模型的精度。 在后续优化中,通过针对特定架构量身定制SE块使用,可以进一步提高效率。

SEBlock各模块的作用
整个SEBlock中主要包含2个模块,sequence,excitation,后面的scale属于常规操作。
Squeeze的作用
在SEblock中的sequence是通过GlobalAvgpooling实现的,为了查看这一步的作用,在论文中作者做了这么一个实验。
- 参数量固定
- 移除GlobalAvgpooling操作
- 移除两个fc层使用1x1卷积代替,保持输出的通道数与原来相同
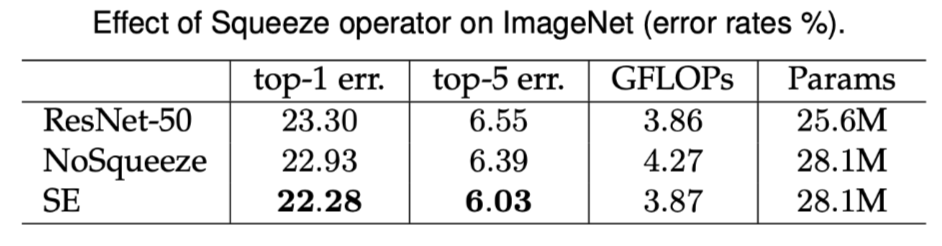
显然,去除了squeeze这一步,在SE模块中,网络无法再直接访问全局特征。在下面的图中通过对比试验,可以看出,去除掉squeeze这一步之后,为模型带了0.7个点的性能损失,并且带来了更多的计算量,而squeeze使用简单地pooling操作,既降低了计算量有带来了性能的提升。
Excitation的作用
这一步很有趣,作者是通过研究分类任务上,网络不同深度上对不同类别的图像和同一类别内的变化。
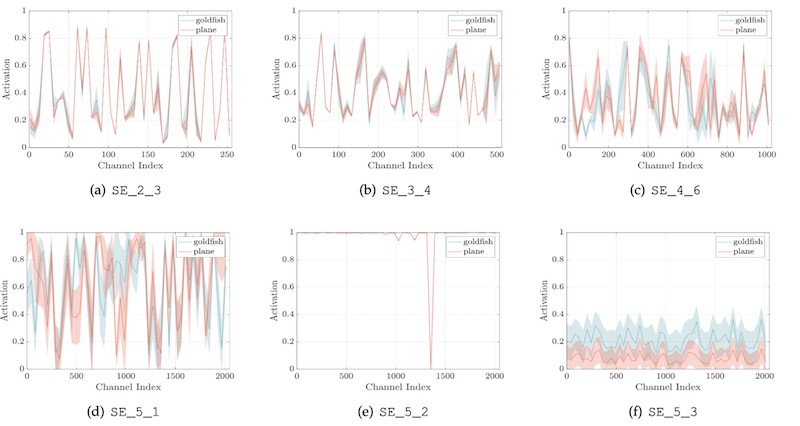
这里选择了语义和外观上都有很大差异的四个类:金鱼,狗,飞机,悬崖。使用每个阶段的最后一个在降采样之前的SE模块,均匀采样50个通道,并计算着50个通道的平均值。从下面这个图可以得到两个结论
- 在较浅的层,不同的类别之间的激活值是很相似的,这有可能是由于CNN的通道权重共享造成的,比如图中的SE2-3
- 随着模型深度的增加,不同类别的激活变得更加特定,这是由于不同类别的输入视觉信号和类别监督信号对特征具有不同的偏好,比如图中的SE4-6,SE5-1
- SE5-2不同的类别的激活表现了趋于饱和的激活状态,在所有激活值取值为1的电商,SE则变成了一个逻辑运算符来判断0/1
- 在SE5-3,后面加上globalpooling就是最后的分类层了,可以看到在不同的类别上的表现趋势很相似,并且变化不大。这表明SE5-2和SE5-3对模型的贡献已经很小了。这表明,可以通过删除这一层,也不会太影响模型的性能,但是可以显著的降低模型的参数量,也验证了随着模型深度的增加,获得的收益越来越小。
实际上这个表现不是SE独有的,任何一个深度学习网络,经过研究发现,浅层特征表达浅层特征,深层特征表达高层特征。

再看一下不同类别激活值的均值和方差的分布,可以明显的看出来,不同类别的均值和方差的分布曲线和激活值的曲线是一致的。