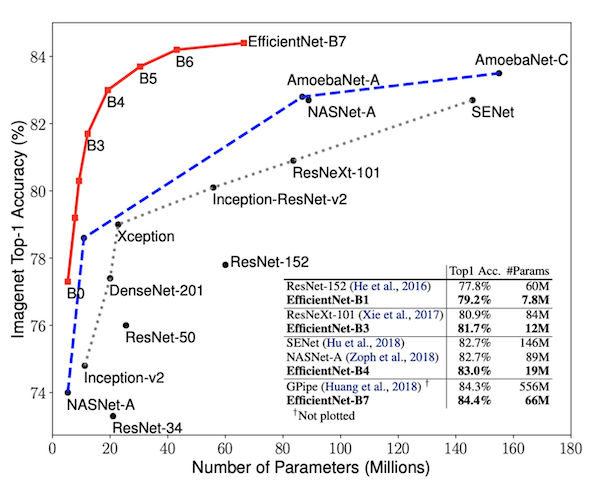
上图为不同模型的参数量和模型ACC曲线,可以看到和EfficientNet对比的网络包含ResNet,SENet,GPipe,Inception,NASNet,DenseNet等目前的主流网络,并且处于领先位置。
Overview
开篇明义,整篇论文一直围绕着下面这张图在进行的
Flops-Acc曲线
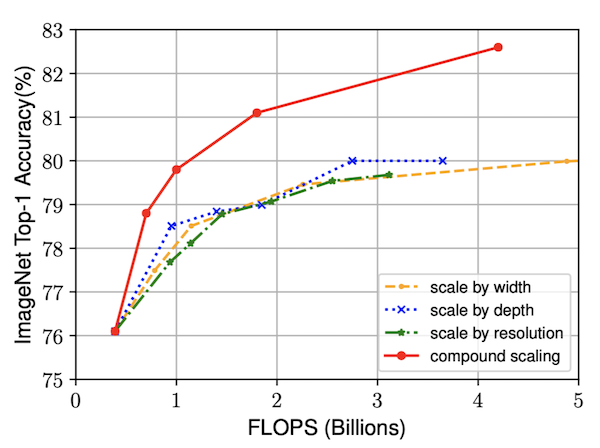
横坐标为模型所需要的算力FLOPS,纵坐标为ACC。在相同的算力需求下,不同的模型策略对应的模型准确率曲线,联合多维度模型优化的策略是优于单个维度优化的策略的。
前几年的发展,在模型设计上为了提高模型的准确率,研究学者从模型的宽度,深度和输入分辨率来进行设计研究。在这个论文中,作者提出了一个思考:能否找到一个规范化的神经网络扩展方法可以同时提高网络的准确率和效率。要实现这点,一个很关键的步骤便是如何平衡宽度、深度和分辨率这三个维度。从Alexnet到2018年的GPipe,人们不断探寻更高效的模型。
| Architecture | Year | Accuracy | Parameters |
|---|---|---|---|
| AlexNet | 2012 | 56.55% | 62M |
| GoogleNet | 2014 | 74.8% | 6.8M |
| SENet | 2017 | 82.7% | 145M |
| GPipe | 2018 | 84.3% | 557M |
Model Acc vs Model Size
很显然,为了提升模型的准确率,往往会带来更多的模型参数,因此我们在选择模型的时候要考虑模型准确率和模型参数里的trade-off,在图表中可以说GoogleNet是全面碾压AlexNet的,因为不论从准确率还是参数里上,GoogleNet都是更优的,目前我们设计ConvNet网络的几个准则
模型压缩
模型剪枝
去掉无法提升模型效率的部分
量化
从数据类型的角度,比如将float转化为int,将float32转化为float16或者float8,可以成倍的缩小模型大小
网络搜索
以MnasNet为例,自动搜索的方法找到最佳的网络深度,卷积内核的宽度,大小等。
模型缩放
仍然使用使用标准CNN网络,例如GoogleNet或ResNet,并通过更改网络的宽度和/或深度或网络的大小来放大(即使用较大的参数)或缩小(即使用较少的参数)。EfficientNet也是采用的这种方式。
模型设计
为了提高模型的效率。扩大网络宽度,深度或分辨率的任何尺寸都可以提高精度,但是对于较大的模型,精度增益会降低。为了追求更好的准确性和效率,在ConvNet扩展过程中平衡网络宽度,深度和分辨率的所有维度至关重要。
关键点就在于:是如何选择应该使网络更深或更宽的范围,或者增加图像分辨率的程度。
Compound Scaling复合模型缩放
这个是在EfficientNet中提出来的,使用复合系数来原则上均匀地缩放宽度,深度和分辨率。在论文中,为了将三个维度结合起来,作者设计了一个公式
$$
\begin{array}{l}
{\text { depth: } d=\alpha^{\phi}} \
{\text { width: } w=\beta^{\phi}} \
{\text { resolution: } r=\gamma^{\phi}} \
s.t. (\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2) \
\alpha \geq 1, \beta \geq 1, \gamma \geq 1
\end{array}
$$
按照论文所述
使用$d$表示模型的深度,$w$表示模型宽度,$\gamma$表示模型的输入分辨率对模型准确性和效率的影响。$\alpha, \beta, \gamma$是由网格搜索的方法得到的三个常数,$\phi$是用户指定的参数,用于控制有多少资源可用于模型缩放,而$\alpha, \beta, \gamma$指定如何分别将这些额外资源分配给网络宽度,深度和分辨率。常规卷积运算的FLOPS与$d$,$w^2$,$\gamma ^2$成正比,即网络深度加倍将使FLOPS加倍,但网络宽度或分辨率加倍将使FLOPS增加四倍。 由于卷积运算通常在ConvNet中占主导地位,因此按照上述公式符合缩放ConvNet将使总FLOPS大约增加$\left(\alpha \cdot \beta^{2} \cdot \gamma^{2}\right)^{\phi}$。在论文中建立约束条件,$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$,这样对于任意网格搜索得到的参数$\alpha, \beta, \gamma$对需要的FLOPS算力的影响被限制为$2^{\phi}$。
模型训练
在EfficientNet中使用的是MnasNet的训练方法,使用的是和MnasNet相同的搜索空间,优化目标为
$$
A C C(m) \times[F L O P S(m) / T]^{w}
$$
其中$A C C(m)$对应着模型的准确率,$[F L O P S(m) / T]^{w}$对应着模型需要的算力,$T$对应着我们一开始设置的需要的算力值,$w=-0.07$是控制准确率和算力之间平衡的超参数
区别于MnasNet的是这里优化的是FLOPS而不是延迟,这是因为模型没有针对专门的设备进行设计,因此使用算力这个值更加合理。经过这中方法,搜索得到模型EfficientNet-B0。
模型结构如下图所示
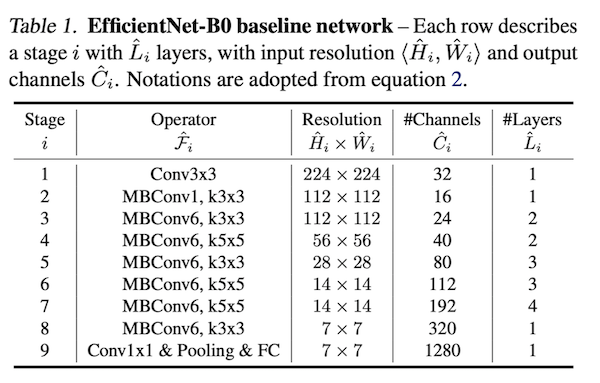
图中的MBConv对应着MobilenetV2中提出的翻转残差模块。可以看到经过MnasNet搜索得到的网络结构跟我们手工设计的网络的确不太一样。
在固定上面公式的$\phi=1$,在约束条件下,经过网格搜索得到最优参数$\alpha=1.2,\beta=1.1,\gamma=1.15$,实际上网格搜索是最暴力的搜索方法,这里不得不说要有强大的计算资源才能进行如此计算。
个人看这个论文的时候被一张图吸引
不同的模型缩放方式对应的激活图
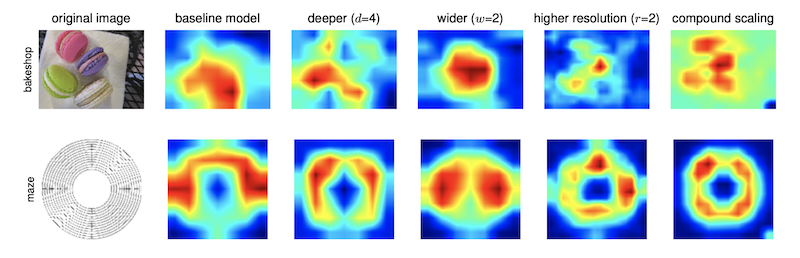
这张图展示了在不同的模型策略下,对应的激活图,可以看到
基础模型,区域信息加大,包含很多噪音特征
模型加深之后,特征变得稀疏,会集中在相对更明显的物体上
模型加宽之后,特征值变得较大,但是区域仍然包含较多噪音
增大输入分辨率,特征会集中在单个实体上,但是特征值很少
符合缩放模型,特征值具有了三者的优势,特征值变大,并且集中在单个实体上。

